以CPU为例,cvm其它指标可以参考,所有指标如下:
| 监控项 | 指标名 |
| CPU 一分钟平均负载 | qce_cvm_cpuloadavg_avg |
| CPU 五分钟平均负载 | qce_cvm_cpuloadavg5m_avg |
| CPU 利用率 | qce_cvm_cpuusage_avg |
| CPU 十五分钟平均负载 | qce_cvm_cpuloadavg15m_avg |
| 基础 CPU 使用率 | qce_cvm_basecpuusage_avg |
| 内存使用量 | qce_cvm_memused_avg |
| 内存利用率 | qce_cvm_memusage_avg |
| 磁盘写流量 | qce_cvm_diskwritetraffic_max |
| 磁盘利用率 | qce_cvm_cvmdiskusage_max |
| 磁盘读流量 | qce_cvm_diskreadtraffic_max |
| TCP 连接数 | qce_cvm_tcpcurrestab_max |
| 内网入包量 | qce_cvm_laninpkg_avg |
| 内网入带宽 | qce_cvm_lanintraffic_avg |
| 内网出包量 | qce_cvm_lanoutpkg_avg |
| 内网出带宽 | qce_cvm_lanouttraffic_avg |
| 外网入包量 | qce_cvm_waninpkg_max |
| 外网入带宽 | qce_cvm_wanintraffic_max |
| 外网出包量 | qce_cvm_wanoutpkg_max |
| 外网出带宽 | qce_cvm_wanouttraffic_max |
| 外网出带宽使用率 | qce_cvm_outratio_max |
| 外网出流量 | qce_cvm_accouttraffic_sum |
| 子机 utc 时间和 ntp 时间差值 | qce_cvm_timeoffset_max |
| GPU 使用率 | qce_cvm_gpuutil_avg |
| GPU 内存使用率 | qce_cvm_gpumemusage_avg |
| GPU 内存使用量 | qce_cvm_gpumemused_avg |
| GPU 内存总量 | qce_cvm_gpumemtotal_avg |
| GPU 功耗使用率 | qce_cvm_gpupowusage_avg |
| GPU 功耗使用量 | qce_cvm_gpupowdraw_avg |
| GPU 功耗总量 | qce_cvm_gpupowlimit_avg |
| GPU 温度 | qce_cvm_gputemp_avg |
| GPU 编码器使用率 | qce_cvm_gpuencutil_avg |
| GPU 解码器使用率 | qce_cvm_gpudecutil_avg |
| GPU是否存在显存页需隔离 | qce_cvm_gpuretiredpagepending_last |
| GPU显存是否发生UCE | qce_cvm_gpueccterminateapp_last |
| vRDMA网卡入包量 | qce_cvm_vrdmainpkt_sum |
| vRDMA网卡出包量 | qce_cvm_vrdmaoutpkt_sum |
| vRDMA网卡发送带宽 | qce_cvm_vrdmaouttraffic_sum |
| vRDMA网卡接收带宽 | qce_cvm_vrdmaintraffic_sum |
一、目标
使用腾讯云自带的 Prometheus 和 Grafana,通过腾讯云云监控导入的 CVM 指标,实现:
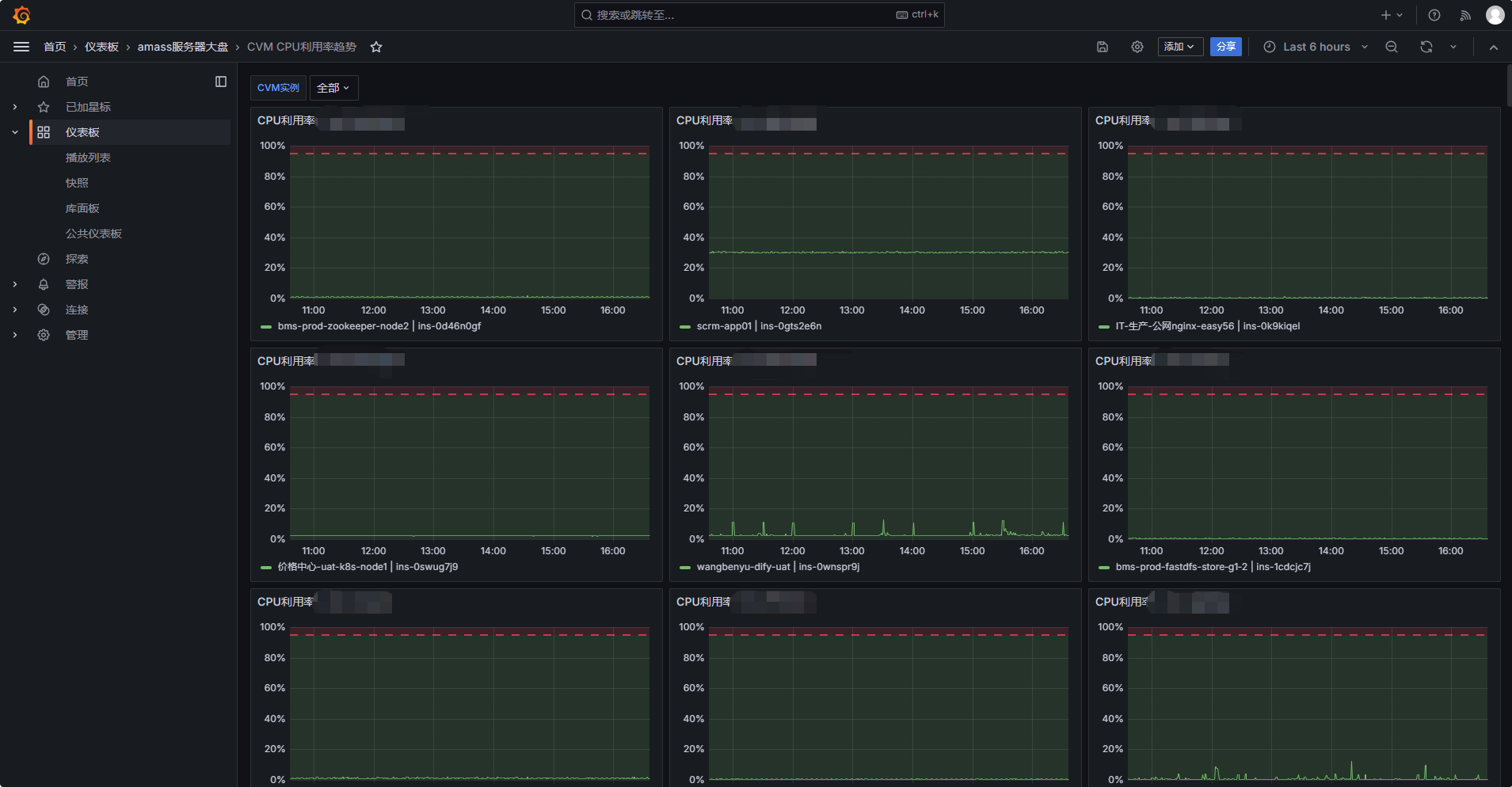
每台 CVM 一个 CPU 利用率小图
每行展示 3 台 CVM
展示最近 30 天 CPU 利用率趋势
左侧 Y 轴为百分比
增加 95% CPU 阈值线
二、前提条件
需要已经完成以下准备:
1. 腾讯云 Prometheus 实例已创建
2. 腾讯云 Grafana 实例已创建或已关联 Prometheus
3. Prometheus 已通过“云监控集成”接入 CVM 云服务器指标
4. Grafana 中可以查询到 qce_cvm_cpuusage_avg 等指标
三、使用的核心指标
CPU 利用率指标:
qce_cvm_cpuusage_avg
常用标签:
instance_id CVM 实例 ID
instance_name CVM 实例名称
instance_region CVM 所在地域
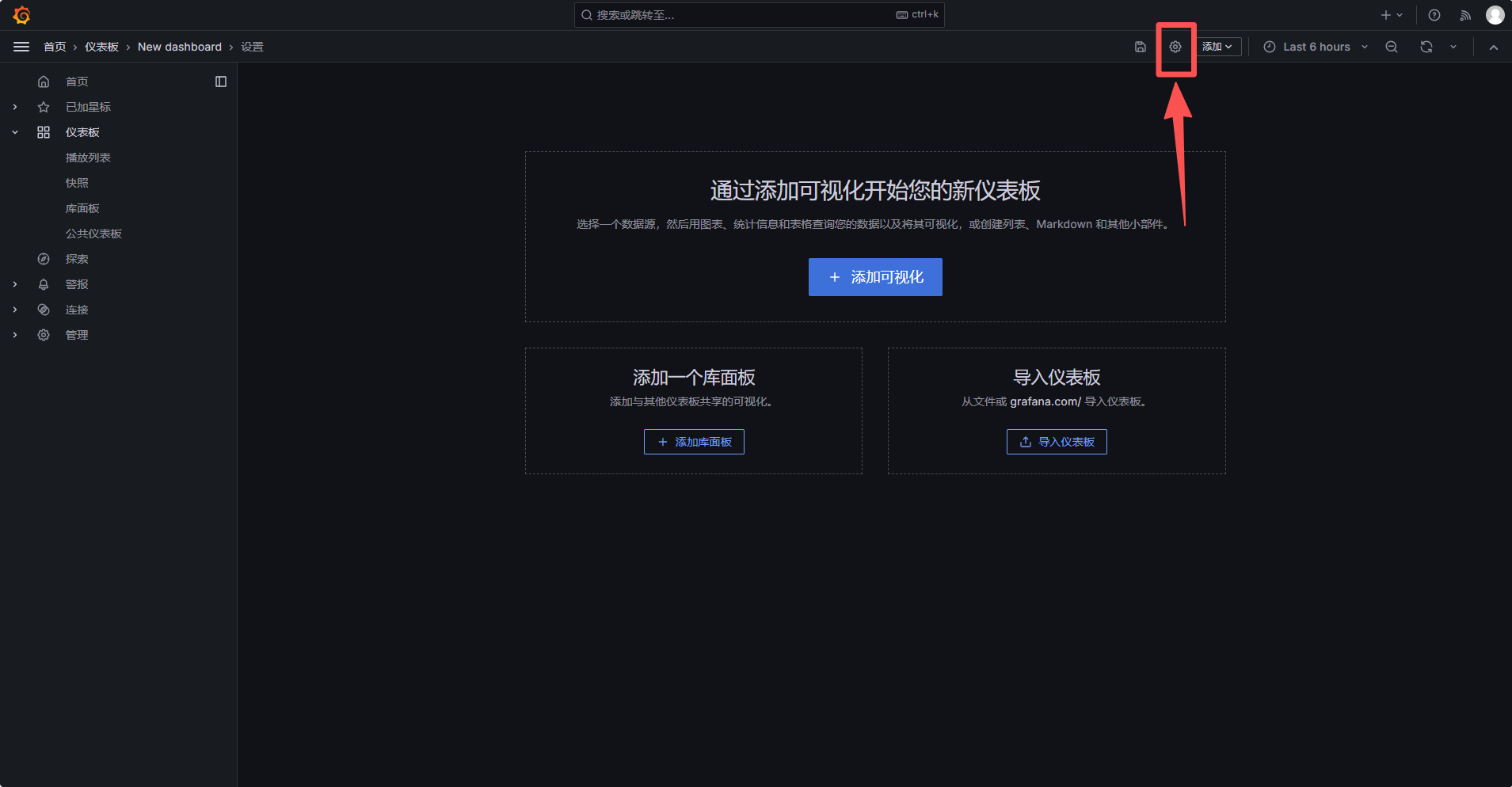
四、新建 Dashboard
进入 Grafana:
五、创建 CVM 实例变量 instance_id
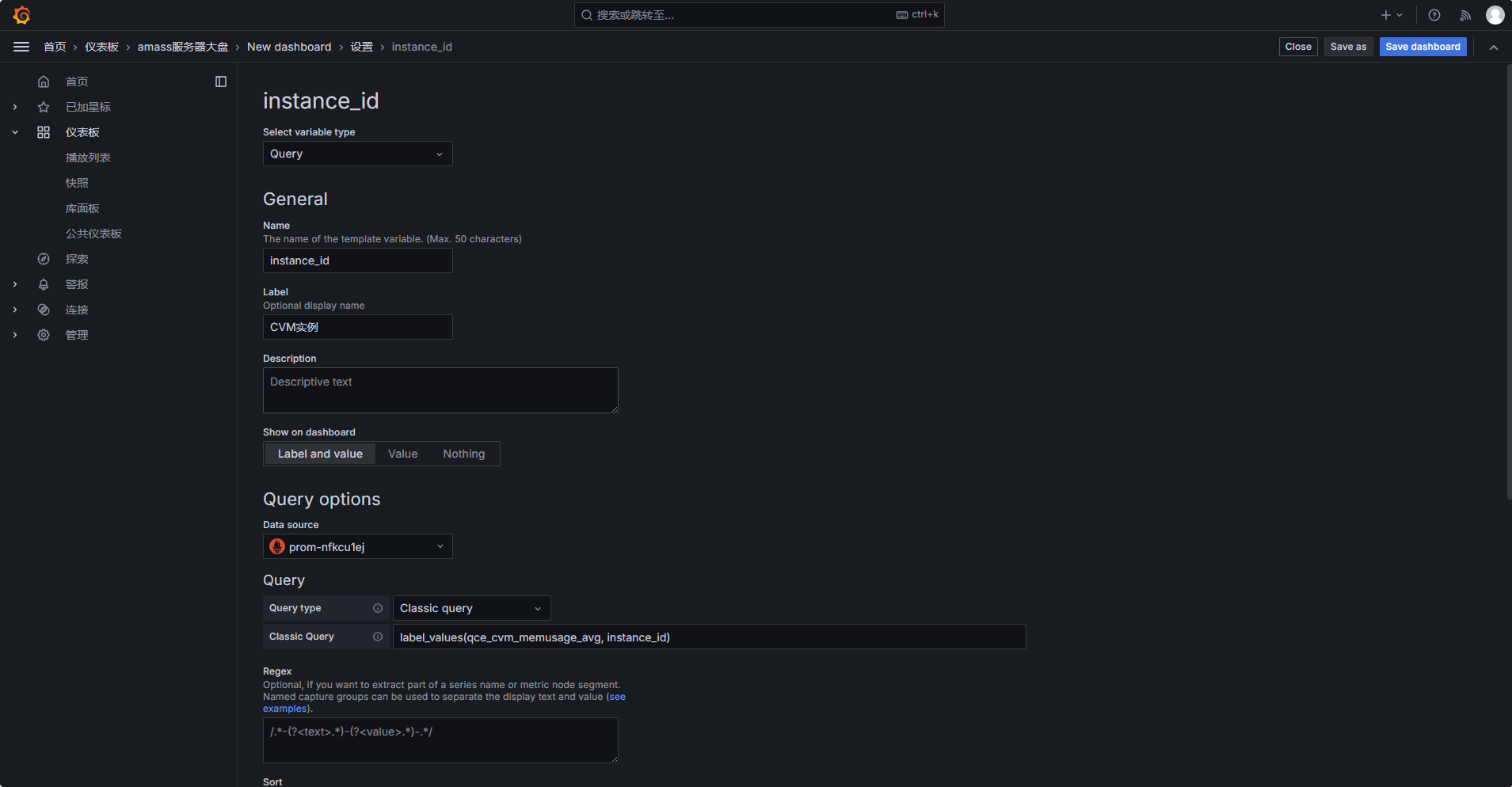
进入 Dashboard 设置:
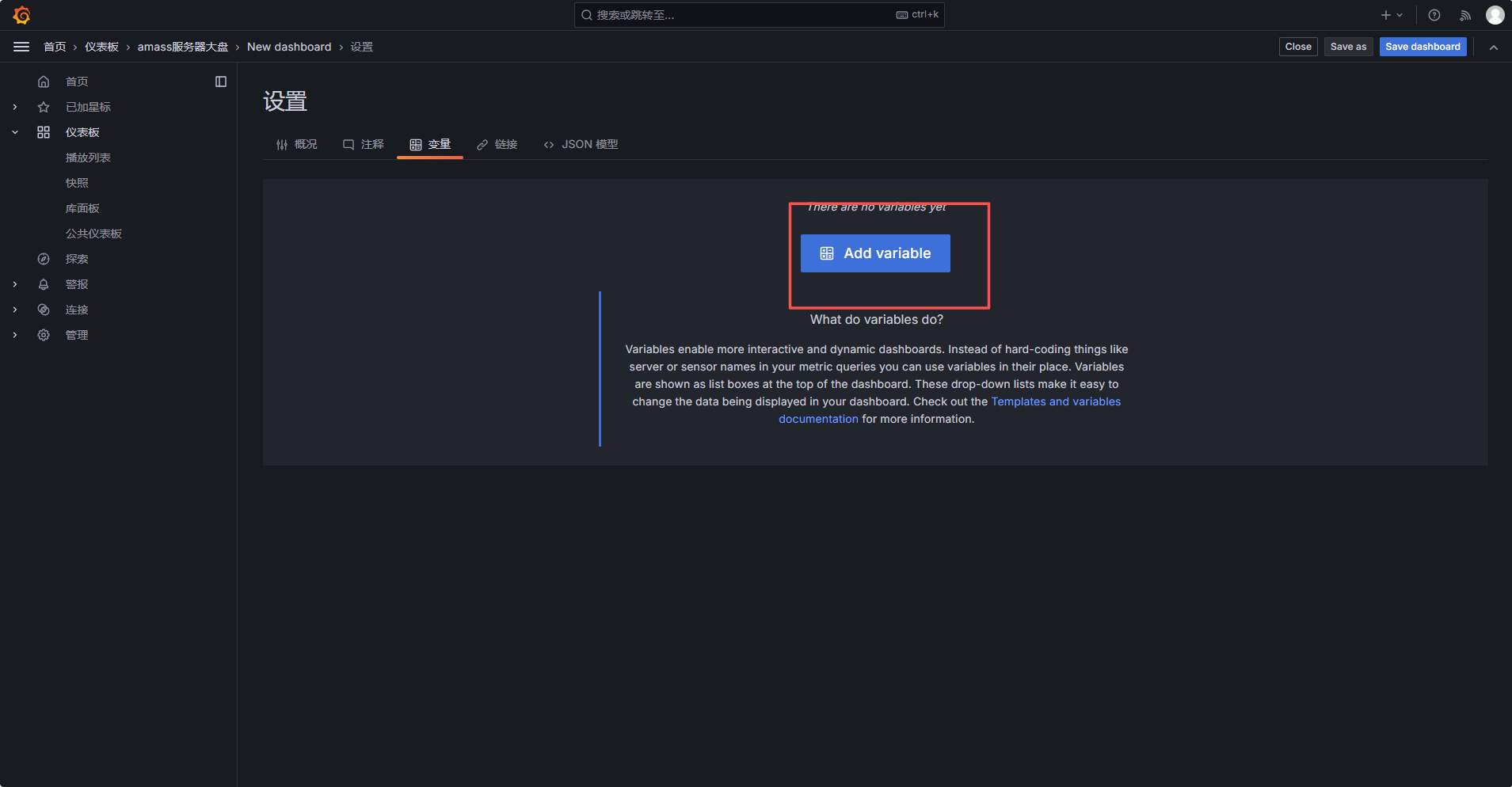
变量配置如下:
Select variable type:Query
Name:instance_id
Label:CVM实例
Data source:选择腾讯云 Prometheus 数据源
Query type:Classic query
Classic Query 填写:
label_values(qce_cvm_cpuusage_avg, instance_id)
继续往下找到:
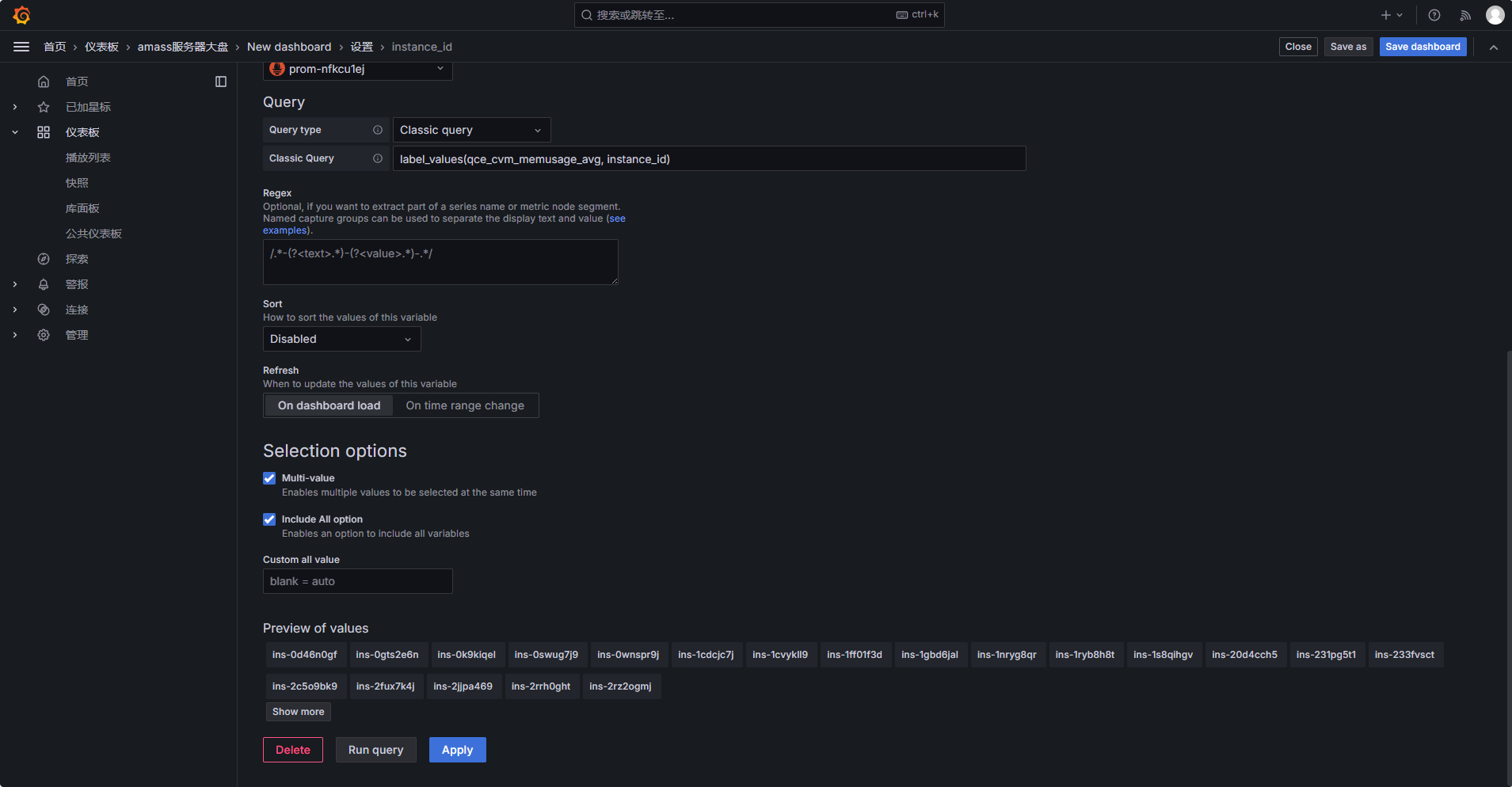
Selection options
打勾:
✔Multi-value
✔Include All option
然后查看页面底部的 Preview values,正常应该能看到类似,如果能看到实例 ID,说明变量创建成功。:
ins-xxxxxxx
ins-yyyyyyy
ins-zzzzzzz
点击Apply
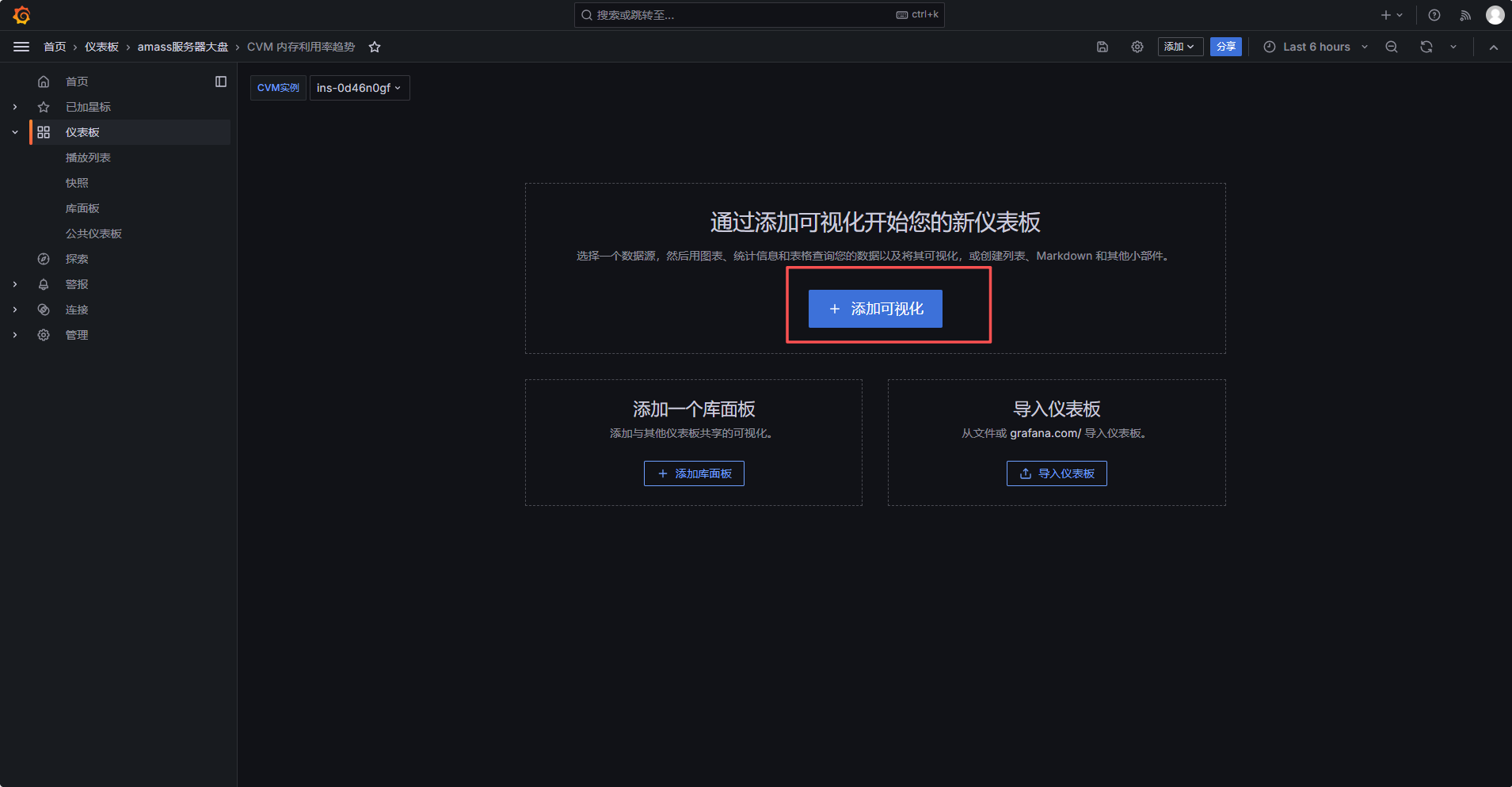
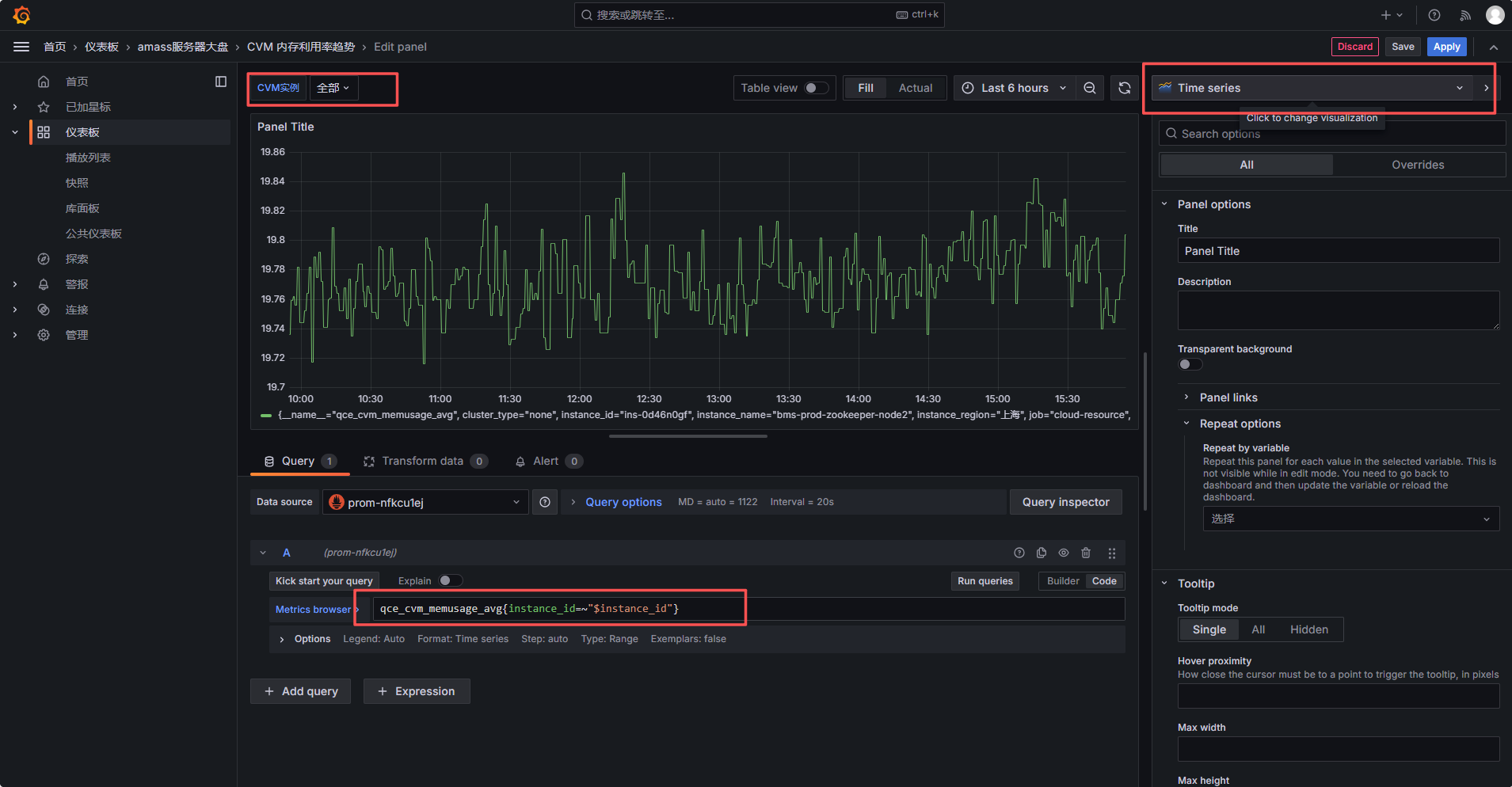
六、新建 CPU 利用率面板
回到 Dashboard,点击添加可视化:
选择数据源,腾讯云 Prometheus:
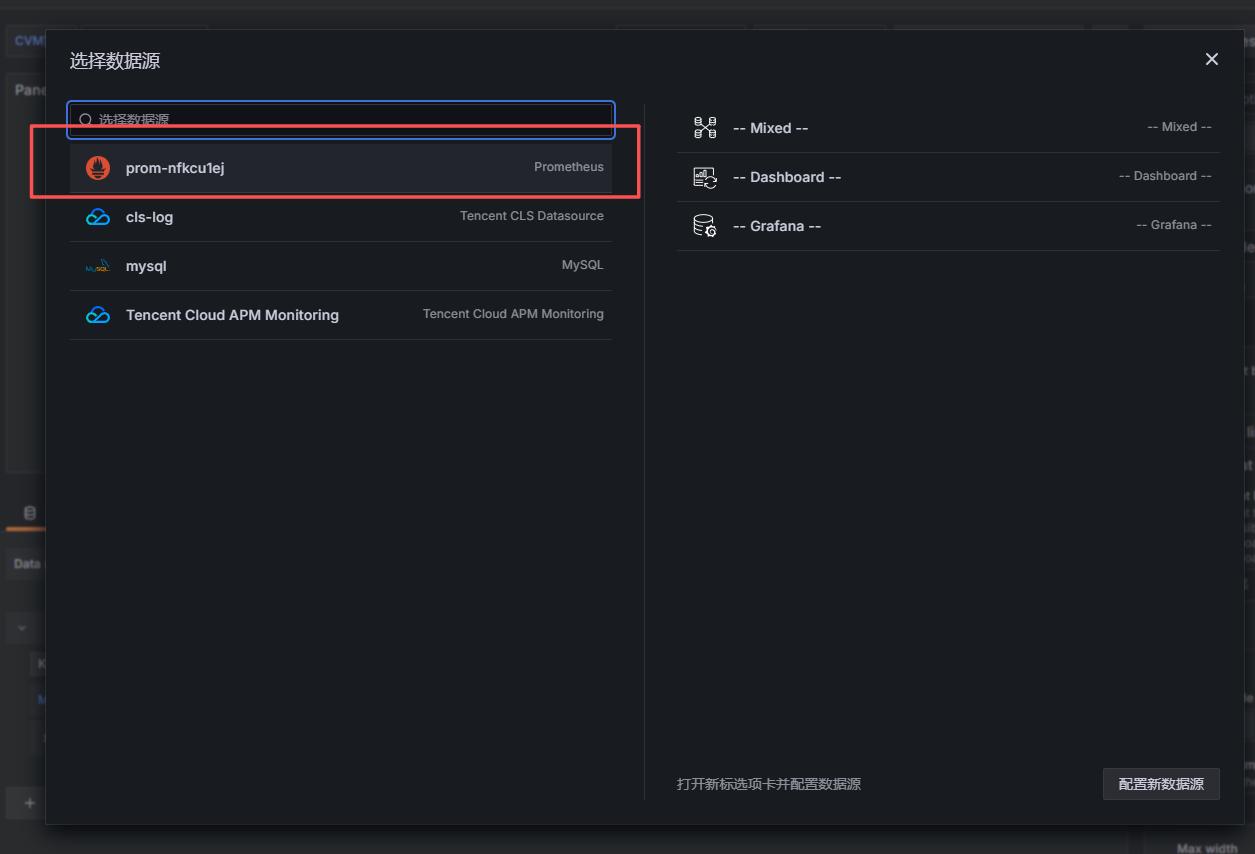
Visualization 选择:Time series,Query 使用:qce_cvm_cpuusage_avg{instance_id=~”$instance_id”} ,注意这里必须使用=~ ,不要写成=,因为 instance_id 变量开启了 Multi-value 和 All,使用正则匹配更稳。
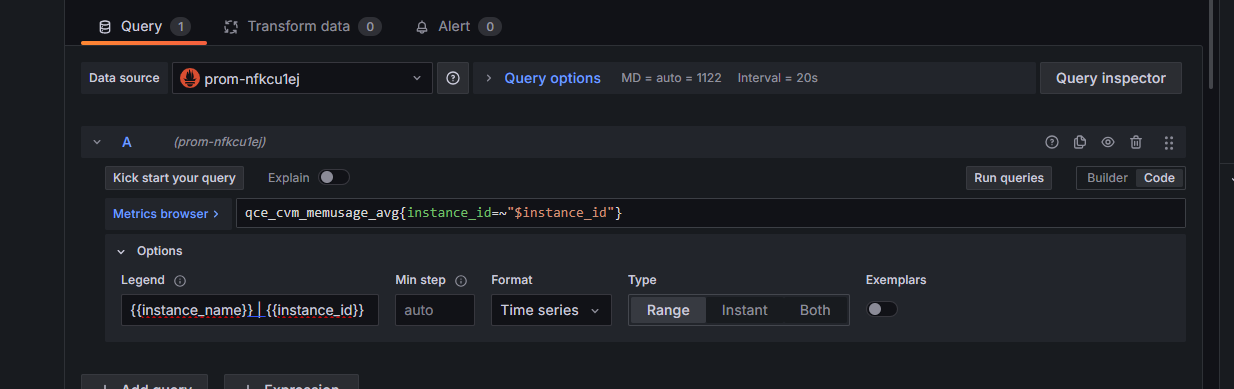
七、设置 Legend 图例
在 Query 下方找到:Options
展开后找到:Legend
把默认的 Auto 改成:{{instance_name}} | {{instance_id}}
这样图例不会显示一长串标签,而是显示:主机名 | 实例ID
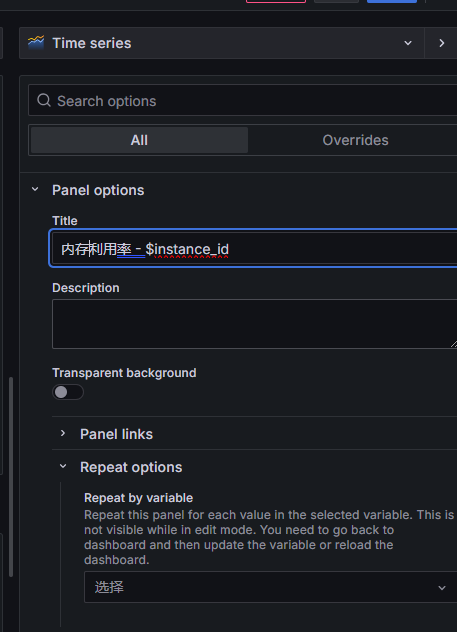
八、设置 Panel Title
右侧配置栏:CPU利用率 – $instance_id
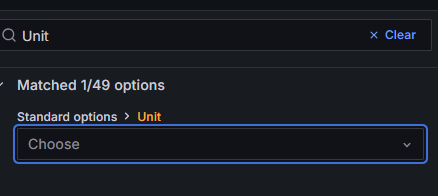
九、设置 Y 轴为百分比
右侧配置栏中,搜索:Unit
设置:Unit:Percent (0-100)
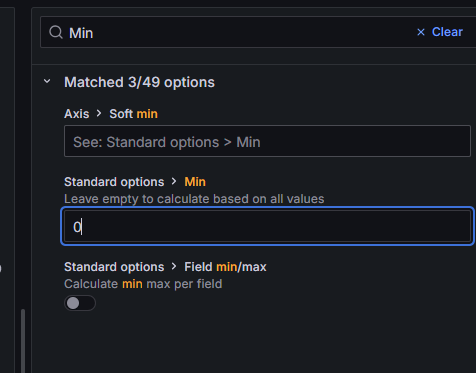
再搜索:Min
设置:Min:0
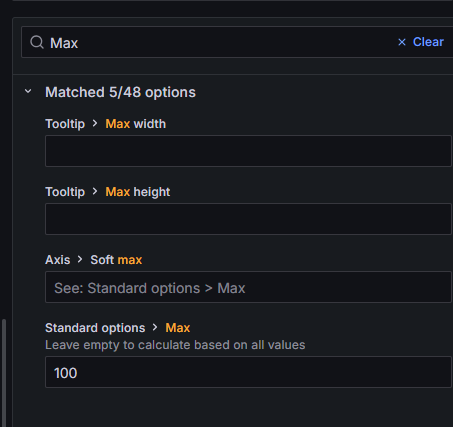
再搜索:Max
设置:Max:100
十、设置左侧 Y 轴
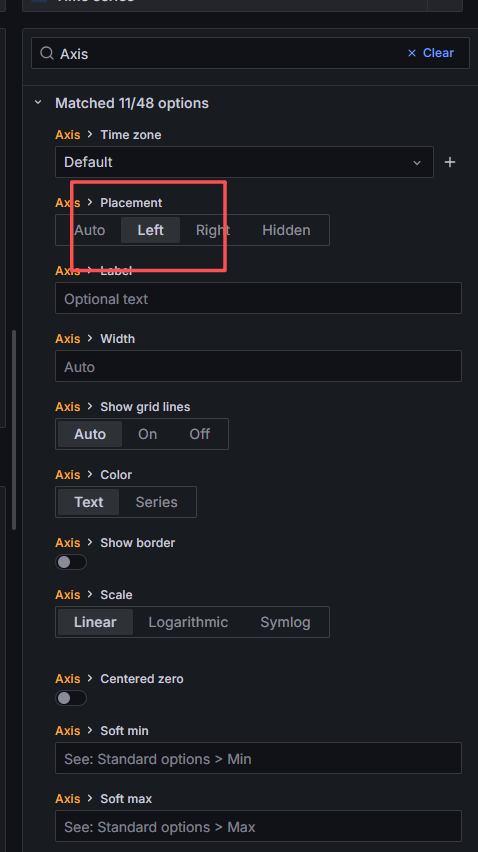
右侧配置栏找到:Axis
设置:Placement:Left
这样 Y 轴会显示在左侧。
十一、设置 95% 阈值线
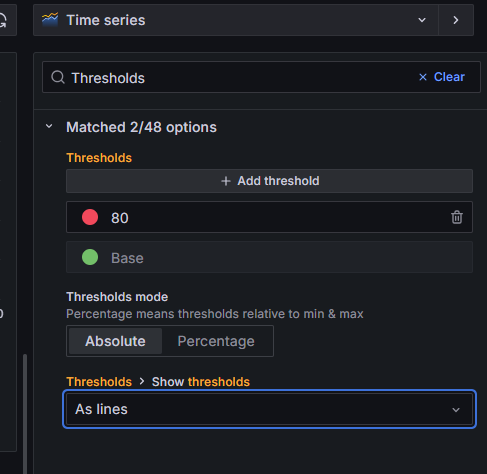
右侧配置栏搜索:Thresholds
配置:
Base:Green
95:Red
Show thresholds:As lines
这样图中会出现一条 95% 的红色阈值线。
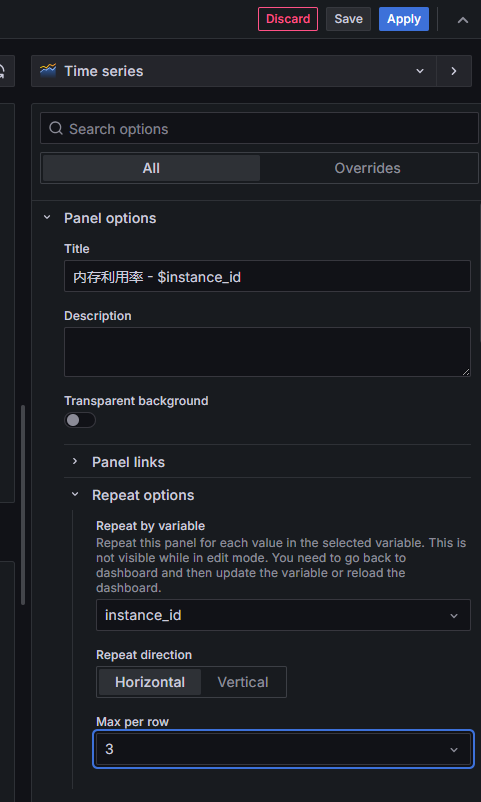
十二、设置每台 CVM 一个小图
这是关键步骤。
在右侧配置栏找到:
Panel options
→ Repeat options
展开后设置:
Repeat by variable:instance_id
Repeat direction:Horizontal
Max per row:3
设置完成后,点击右上角:Apply
十三、选择全部 CVM
回到 Dashboard 顶部变量选择框:CVM实例,选择:全部,然后刷新 Dashboard。此时 Grafana 会根据 instance_id 自动生成多个 CPU 小图: